



Transient Performance: Scoping the Challenges for SDN
Neil Davies and Peter Thompson, Predictable Network Solutions Ltd.
IEEE Softwarization, July 2017
The delivered real-time performance of networks is becoming ever more important, especially as applications increasingly become interacting collections of micro-services, dependent on each other and the connectivity between them. Typical network performance measures such as speed tests or MRTG reports represent only averages over periods that are very long compared to the response times of such services. The assumption that such averages provide a reliable guide to the performance over much shorter intervals is just that: an assumption, and one that becomes increasingly questionable as new technologies such as SDN introduce rapid and frequent network reconfigurations.
In our earlier article “Performance Contracts in SDN Systems” we presented ‘network performance’ as the absence of ‘quality impairment’ (in the same way that a ‘high-performance’ analog connection is one that introduces minimal noise and distortion). We called this impairment ‘∆Q’. It has several sources, including the time for signals to travel between the source and destination and the time taken to serialize and deserialize the information. In packet-based networks, statistical multiplexing is an additional source of impairment, making ∆Q an inherently statistical measure. It can be thought of as either the probability distribution of what might happen to a packet transmitted at a particular moment from source A to destination B or as the statistical properties of a stream of such packets. ∆Q captures both the effects of the network’s structure and extent, and the additional impairment due to statistical multiplexing.
As discussed in the previous article, whether an application delivers fit-for-purpose outcomes depends entirely on the ‘magnitude’ of ∆Q and the application’s sensitivity to it. The outcome of statistical multiplexing is affected by several factors, of which load is one; since capacity is finite, no network can offer bounded impairment to an unbounded applied load. What an application really requires from the network is the transfer of an amount of information with a bounded impairment, depending on what the application can tolerate. We previously presented a formal representation of such a requirement, called a ‘Quantitative Timeliness Agreement’ or ‘QTA’, which provides a way for an application and a network to ‘negotiate’ performance. In effect, the application ‘agrees’ to limit its applied load in return for a ‘promise’ from the network to transport it with suitably bounded impairment.
As SDN paths are composed of routes built upon hop-by-hop connections, each of which will introduce some ‘quality impairment’ (∆Q), truly effective orchestration requires a comprehensive understanding of how quality impairment accrues along such paths. This is a prerequisite to being able to budget and plan to deliver appropriately bounded quality impairment, which underpins fit-for-purpose end-to-end network transport.
Measurement and Decomposition of ∆Q
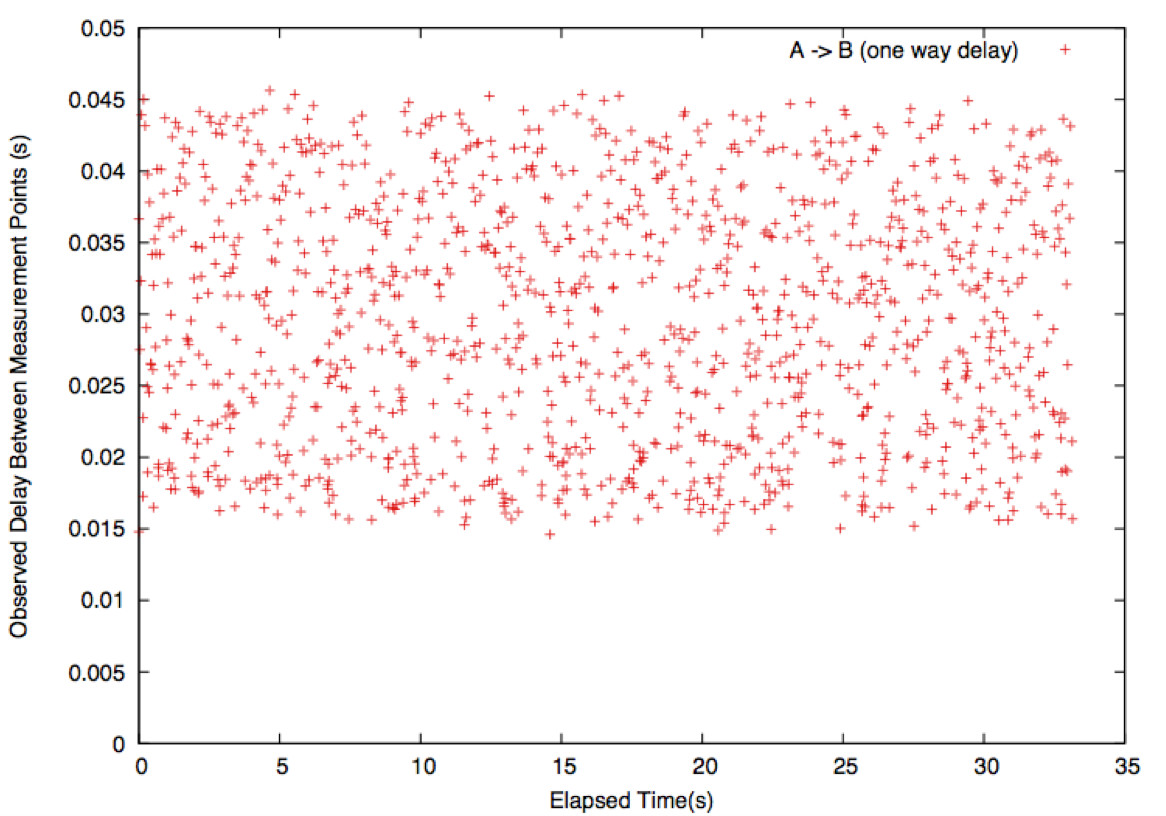
∆Q can be estimated by measuring the point-to-point delays of a sequence of packets. A typical experimental measurement of ∆Q looks like the figure above: a series of packets are sent from A to B, and the time taken for each one is measured; different packets experience different delays, but it’s unclear what sense to make of this data.
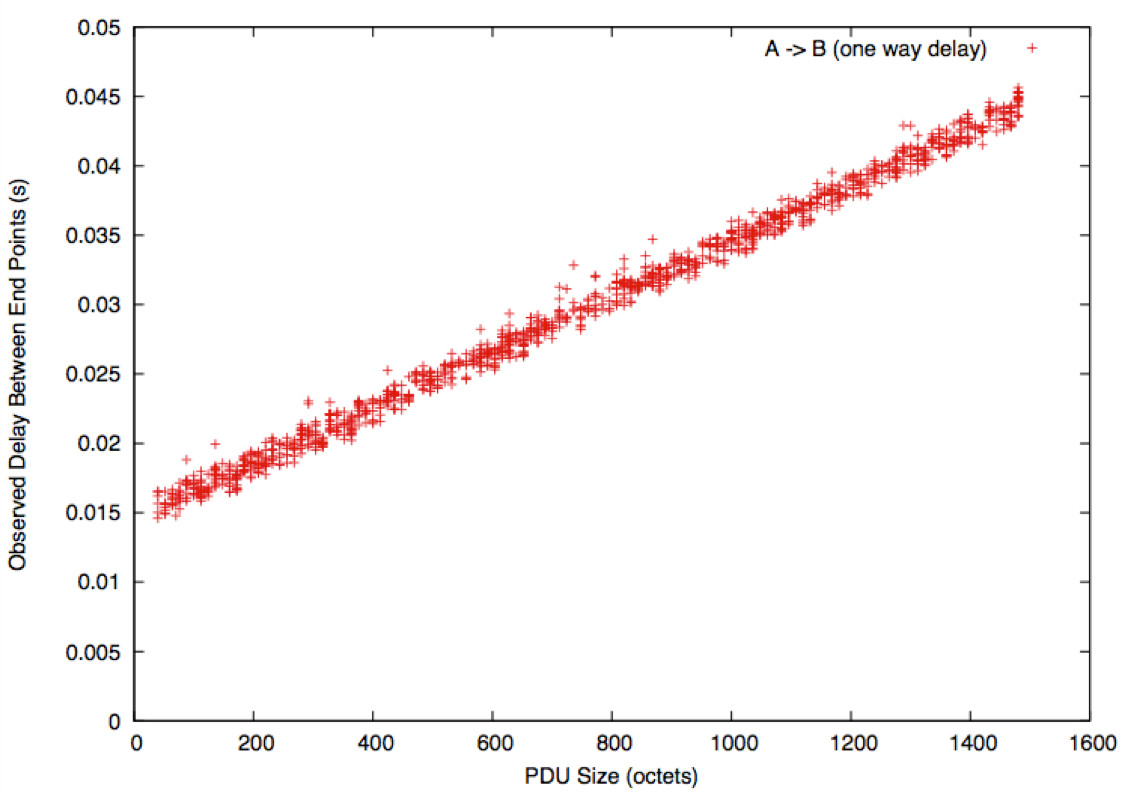
One reason for the variability is that the packets are of different sizes. The figure above shows the same data sorted by packet size; structure now begins to emerge.
There is a boundary line. Packets on the line experienced a network where all buffers were empty; those above had to wait for other traffic in buffers.
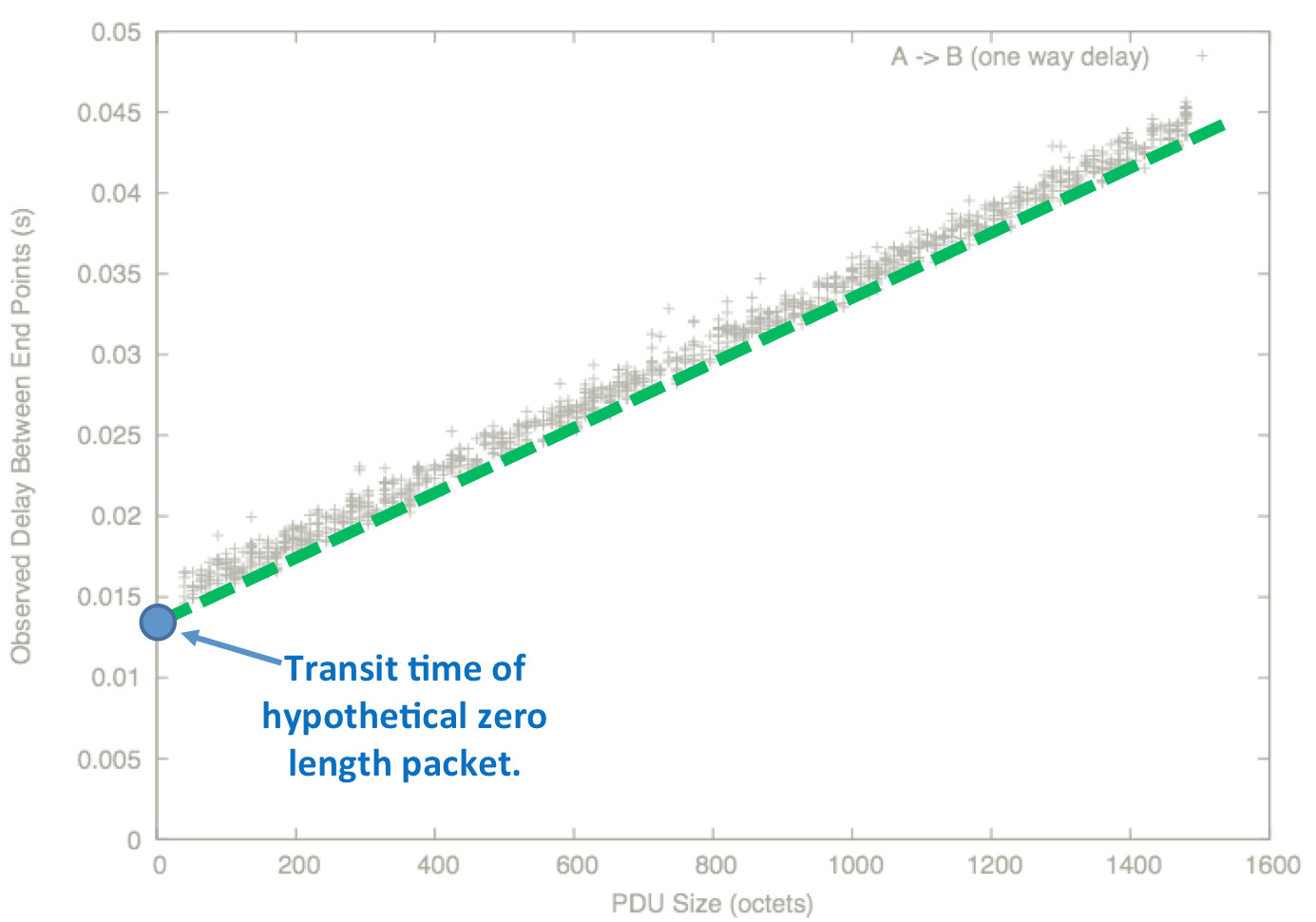
Extrapolating this line to a ‘zero size’ packet gives a measure of the minimum delay: this is called ∆Q|G, or just ‘G’. This incorporates:
- Geographical factors (~ distance/c);
- Media access effects, particularly when resources are shared (such as with WiFi and 3G);
- Per-packet overheads such as router lookups.
It represents the irreducible cost of transporting a SDU (service data unit). Note that this may, in itself, be a probability distribution (and usually is).
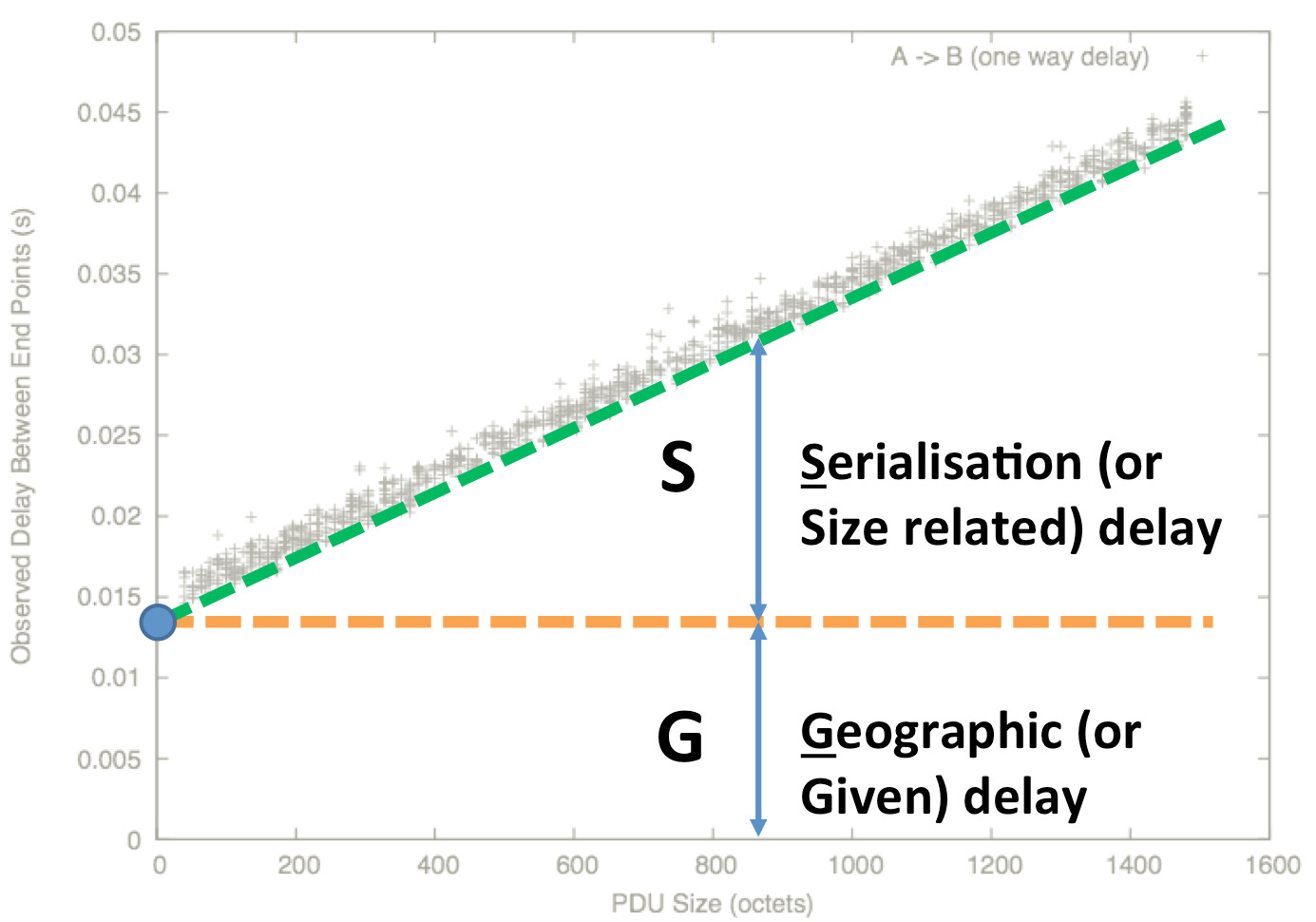
Packets with bigger payloads experience more structural delay: it takes longer to turn the packet into a bitstream, and back again into a packet at the next network element. This is
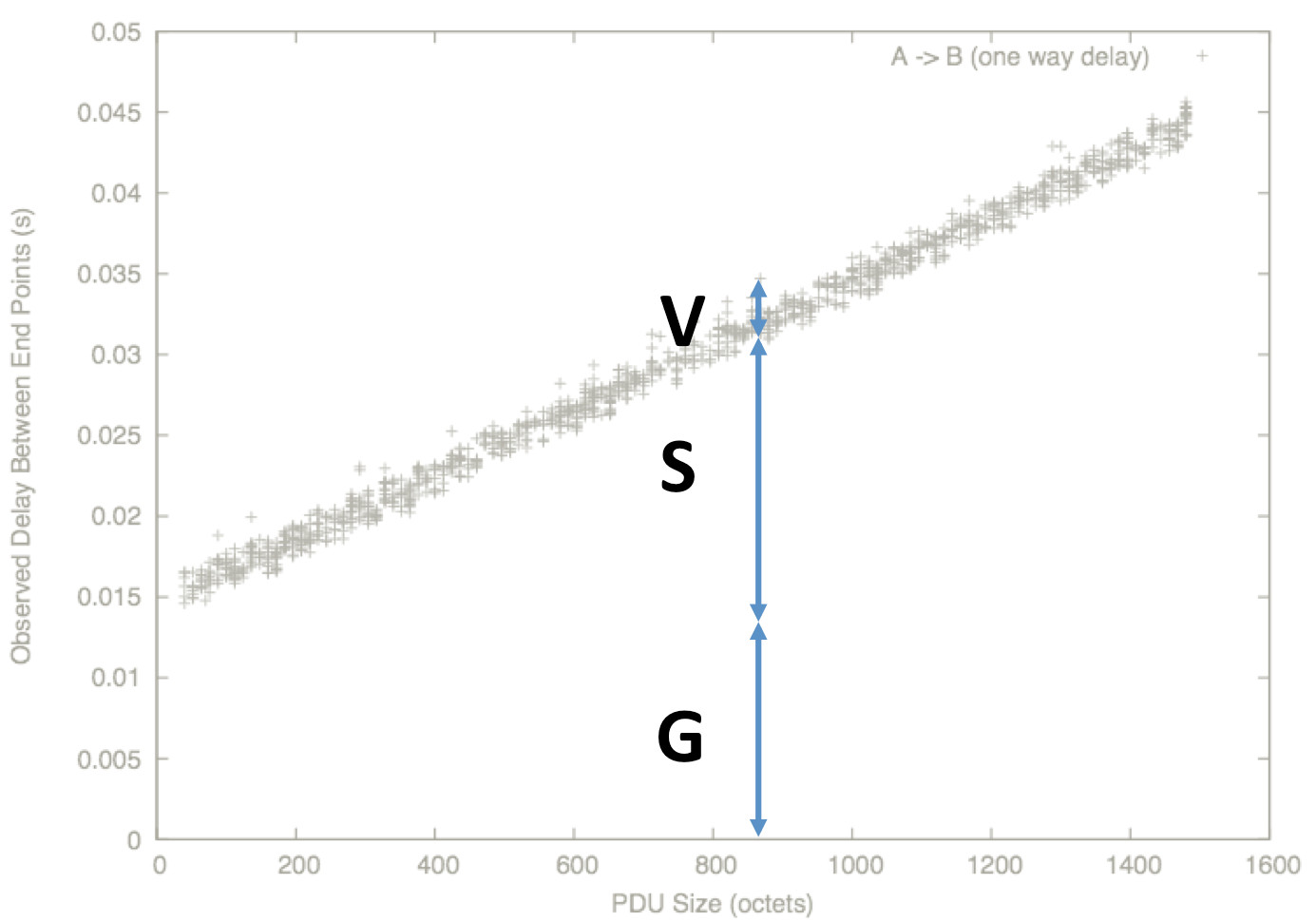
called ∆Q|S, or just ‘S’, and is a function from packet size to delay[1].
The remainder of the delay is not structural, but is induced by offering a non-zero load to the shared transmission supply. This remaining delay is called ∆Q|V, or just ‘V’; network elements have choices over how to allocate this delay.
Each of those components could also contribute to loss.
All ∆Q is (everywhere and always) comprised of these three basic elements. G, S, and V form a set of ‘basis vectors’ for the overall ∆Q. It is important to remember that it is this overall ∆Q that determines application outcomes; but for understanding how the network gives rise to ∆Q, the decomposition into G, S and V is very helpful.
Variability of Network Performance
Repeated measurements of ∆Q over the same path show striking patterns of variability.
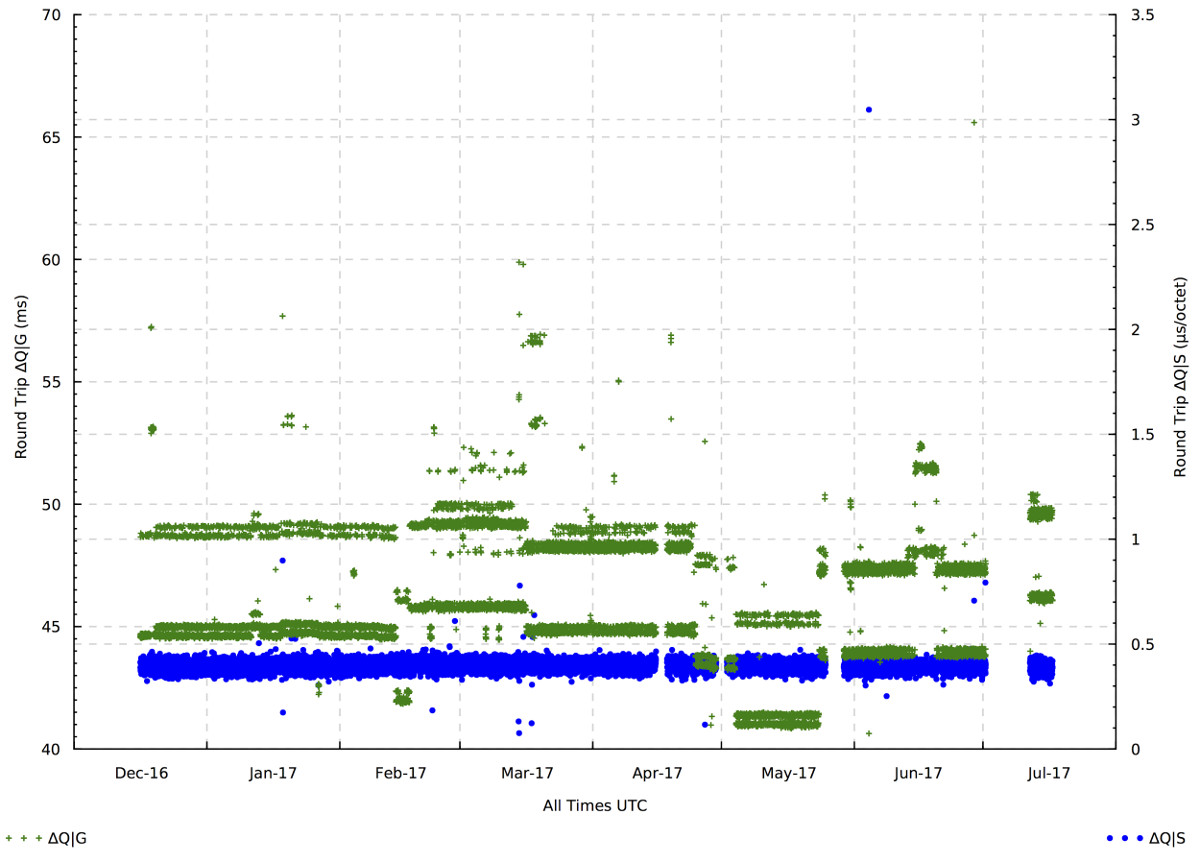
The diagram above shows the G and S components of the measured ∆Q for the round-trip between an endpoint connected to a GPON access network and a server in a datacenter 1600km away. Measurements were taken three times per hour; S is mostly constant, but G shows interesting variations. The absolute minimum round-trip time determined by the speed of light is 11ms; however, light travels more slowly in glass than in space; fibers do not follow the shortest possible path between two arbitrarily chosen points; and packets must pass through intermediate switches and routers, so a minimum measured G of 42ms is entirely reasonable. What is notable is how G varies between one measurement and the next, typically by up to 10ms, presumably due to routing choices.
When such choices are made on a connection-by-connection basis they are unlikely to be problematic, however the next diagram shows a sudden shift in delay during the course of a single measurement:
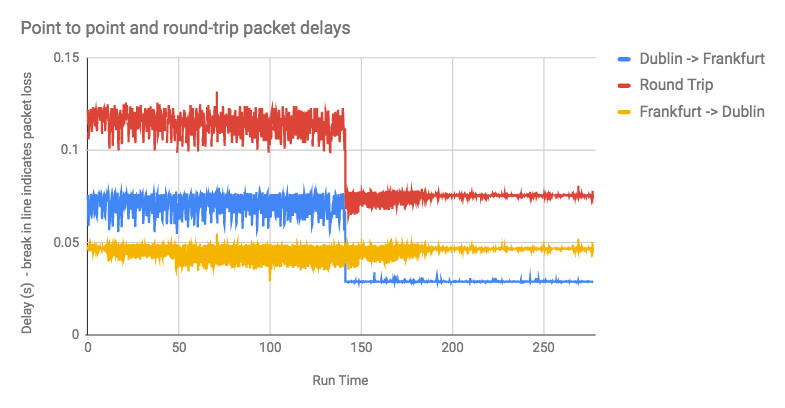
Each point shows the delay for an individual packet between data centers in Dublin and Frankfurt (approximately 1000km apart, a 6ms round-trip as the photon flies). It can be seen that the base delay (∆Q|G) suddenly drops by about 40ms, again presumably because of a routing change, which could be problematic for many applications. Ongoing measurement of this route shows that changes like this (though not often of this magnitude) occur several times per week.
Challenge for SDN
Softwarization of networks makes changes of configuration, for example bearer and routing options, much easier to perform, and hence will probably increase their frequency substantially. It is tempting to assume that, provided connectivity is maintained and capacity is sufficient, such changes can be made freely and without consequences. The examples above show that, even in the current, largely static situation, there are substantial variations and sharp transients in performance that could have significant impacts on real-time and highly interactive services.
The challenge for the SDN ecosystem is to better understand and model these dynamics of network performance. Given that individual route choices can cause application-affecting changes in delivered quality impairment, issues of both consistency and absolute value arise, particularly as an application may open up multiple connections to a single peer. As we have shown above, quality impairment can change hour-by-hour or even second-by-second in existing (non-SDN) solutions. How can SDN rise to the challenge of delivering better and more consistent services than we have today, with better control over the delivered quality impairment and hence more satisfactory application and customer experience?
[1] ∆Q|S is not necessarily a straight line: it may have a more complex structure depending on media quantisation (e.g. ATM cells, WiFi) and bearer allocation choices (e.g. 3GPP).
 Neil Davies is an expert in resolving the practical and theoretical challenges of large scale distributed and high-performance computing. He is a computer scientist, mathematician and hands-on software developer who builds both rigorously engineered working systems and scalable demonstrators of new computing and networking concepts. His interests center around scalability effects in large distributed systems, their operational quality, and how to manage their degradation gracefully under saturation and in adverse operational conditions. This has lead to recent work with Ofcom on scalability and traffic management in national infrastructures.
Neil Davies is an expert in resolving the practical and theoretical challenges of large scale distributed and high-performance computing. He is a computer scientist, mathematician and hands-on software developer who builds both rigorously engineered working systems and scalable demonstrators of new computing and networking concepts. His interests center around scalability effects in large distributed systems, their operational quality, and how to manage their degradation gracefully under saturation and in adverse operational conditions. This has lead to recent work with Ofcom on scalability and traffic management in national infrastructures.
Throughout his 20-year career at the University of Bristol he was involved with early developments in networking, its protocols and their implementations. During this time he collaborated with organizations such as NATS, Nuclear Electric, HSE, ST Microelectronics and CERN on issues relating to scalable performance and operational safety. He was also technical lead on several large EU Framework collaborations relating to high performance switching. Mentoring PhD candidates is a particular interest; Neil has worked with CERN students on the performance aspects of data acquisition for the ATLAS experiment, and has ongoing collaborative relationships with other institutions.
 Peter Thompson became Chief Technical Officer of Predictable Network Solutions in 2012 after several years as Chief Scientist of GoS Networks (formerly U4EA Technologies). Prior to that he was CEO and one of the founders (together with Neil Davies) of Degree2 Innovations, a company established to commercialize advanced research into network QoS/QoE, undertaken during four years that he was a Senior Research Fellow at the Partnership in Advanced Computing Technology in Bristol, England. Previously he spent eleven years at STMicroelectronics (formerly INMOS), where one of his numerous patents for parallel computing and communications received a corporate World-wide Technical Achievement Award. For five years he was the Subject Editor for VLSI and Architectures of the journal Microprocessors and Microsystems, published by Elsevier. He has degrees in mathematics and physics from the Universities of Warwick and Cambridge, and spent five years doing research in general relativity and quantum theory at the University of Oxford.
Peter Thompson became Chief Technical Officer of Predictable Network Solutions in 2012 after several years as Chief Scientist of GoS Networks (formerly U4EA Technologies). Prior to that he was CEO and one of the founders (together with Neil Davies) of Degree2 Innovations, a company established to commercialize advanced research into network QoS/QoE, undertaken during four years that he was a Senior Research Fellow at the Partnership in Advanced Computing Technology in Bristol, England. Previously he spent eleven years at STMicroelectronics (formerly INMOS), where one of his numerous patents for parallel computing and communications received a corporate World-wide Technical Achievement Award. For five years he was the Subject Editor for VLSI and Architectures of the journal Microprocessors and Microsystems, published by Elsevier. He has degrees in mathematics and physics from the Universities of Warwick and Cambridge, and spent five years doing research in general relativity and quantum theory at the University of Oxford.
Editor:
 Laurent Ciavaglia is currently senior research manager at Nokia Bell Labs where he coordinates a team specialized in autonomic and distributed systems management, inventing future network management solutions based on artificial intelligence.
Laurent Ciavaglia is currently senior research manager at Nokia Bell Labs where he coordinates a team specialized in autonomic and distributed systems management, inventing future network management solutions based on artificial intelligence.
In recent years, Laurent led the European research project UNIVERSELF (www.univerself-project.eu) developing a unified management framework for autonomic network functions. , has worked on the design, specification and evaluation of carrier-grade networks including several European research projects dealing with network control and management.
As part of his activities in standardization, Laurent participates in several working groups of the IETF OPS area and is co-chair of the Network Management Research Group (NRMG) of the IRTF, member of the Internet Research Steering Group (IRSG). Previously, Laurent was also vice-chair of the ETSI Industry Specification Group on Autonomics for Future Internet (AFI), working on the definition of standards for self-managing networks.
Laurent has co-authored more than 80 publications and holds 35 patents in the field of communication systems. Laurent also acts as member of the technical committee of several IEEE, ACM and IFIP conferences and workshops, and as reviewers of referenced international journals, and magazines.
Subscribe to IEEE Softwarization
Join our free SDN Technical Community and receive IEEE Softwarization.
Article Contributions Welcomed
Download IEEE Softwarization Editorial Guidelines for Authors (PDF, 122 KB)
If you wish to have an article considered for publication, please contact the Managing Editor at sdn-editor@ieee.org.
Past Issues
IEEE Softwarization Editorial Board
Laurent Ciavaglia, Editor-in-Chief
Mohamed Faten Zhani, Managing Editor
TBD, Deputy Managing Editor
Syed Hassan Ahmed
Dr. J. Amudhavel
Francesco Benedetto
Korhan Cengiz
Noel Crespi
Neil Davies
Eliezer Dekel
Eileen Healy
Chris Hrivnak
Atta ur Rehman Khan
Marie-Paule Odini
Shashikant Patil
Kostas Pentikousis
Luca Prete
Muhammad Maaz Rehan
Mubashir Rehmani
Stefano Salsano
Elio Salvadori
Nadir Shah
Alexandros Stavdas
Jose Verger