



NFV: From CI/CD to Hypervisor or Container Based Deployments
NFV: From CI/CD to Hypervisor or Container Based Deployments
Marie-Paule Odini, HPE
With NFV, Network Function Virtualization, the whole process starts with the design of the Virtualized Network Function (VNF). This is generally done by a supplier of the VNF, typically a vendor. This VNF is then sold to a service provider who will integrate this VNF in his environment to enhance or deploy a new service.
This process takes several steps, both on the supplier side and then on the service provider side, before, during and after deployment. It is more and more automated with closed loop and iterations to ensure best in class services, no service downtime, and constant feature enhancements of the service environment to remain competitive.
CI/CD: Continuous Integration/Continuous Delivery
Devops, Delivery and Operations, or CI/CD Continuous Integration/Continuous Delivery are terms now commonly used in software development with agile methods using iterative models and more and more automated and collaborative tools.
Continuous Integration is typically used during the “development” process of a software using a set of tools such as coding environment, library access, interpreter/compiler, tools to combine different piece of code, build, testing environment with programmatic access and smooth integration between each component, allowing collaboration and iterative process until test results allow to move to next steps which is Continuous Delivery.
Continuous Delivery is the process that delivers a piece of software to a production environment. It takes the software and a set of metadata that describes the environment required to execute this software, the dependencies, maybe some test routines, expected test results, some test scripts from Continuous Integration and pushes this into a system that will combine this code with other pieces of code that will constitute the service or a bigger component of service. The continuous Delivery will go through some configuration of the environment, the upload of the software to the production environment, the configuration of the software, some tests, and few iterations until the deployment tests results are satisfactory. The next phase will be operation of the live service.
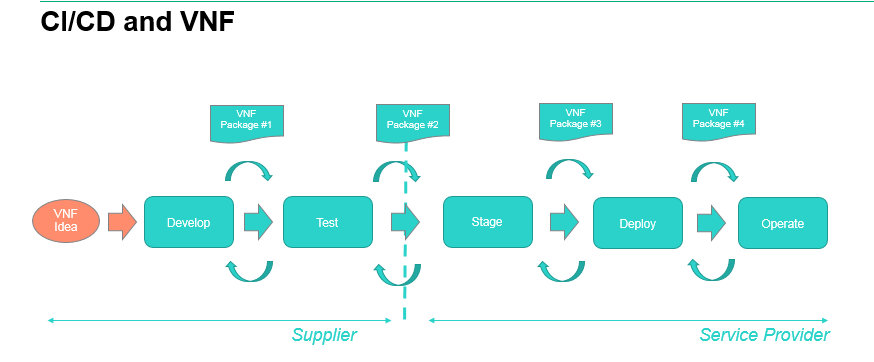
In an NFV environment, where VNF are provided by a set of suppliers, to a service provider that generally assembles the different VNF to deliver a service, the different steps are generally:
- On the supplier side:
- Develop VNF
- Test VNF
- On the Service Provider side:
- Stage VNF
- Deploy VNF
- Operate the VNF as part of the live service
At each stage in the process, a different set of tools is used to perform different tasks, and a VNF package is passed with the application executable code (image) and some artifacts necessary for the next step.
Typically from Develop to Test, the image is passed with a VNF Descriptor that describes the characteristics of the resources needed for that VNF to run, maybe a VNF Manager or some lifecycle management scripts, maybe a config file to configuration the VNF for the tests: this constitutes VNF Package #1.
From Test to Stage: VNF Package #2 may be very similar to VNF Package #1 but include some test scripts and expected test results.
Each step can be used to support the refinement of both functional and non-functional aspects (such as performance, resource consumption and security). Early steps ensure the functional completeness, middle stages permit the profiling of performance and assessment of security. Latter stages take these characterized VNFs and specialize them to the service provider’s environment, such as SDN support requirements specific to the service provider and how the resulting SDN/NFV components would interact with the suppliers’ system integrity and fault recovery processes for instance.
At each step, the VNF package and embedded test artifacts are tuned to include results from that latest step and prepare for the next one. CI/CD and VNF virtualization.
As defined by ETSI NFV SWA specifications, a VNF is typically a set of VNFC (VNF Component). Each VNFC being deployed on a virtualization container. ETSI NFV is agnostic of the virtualization container being used: hypervisor based or container such as Linux container or Docker for instance.
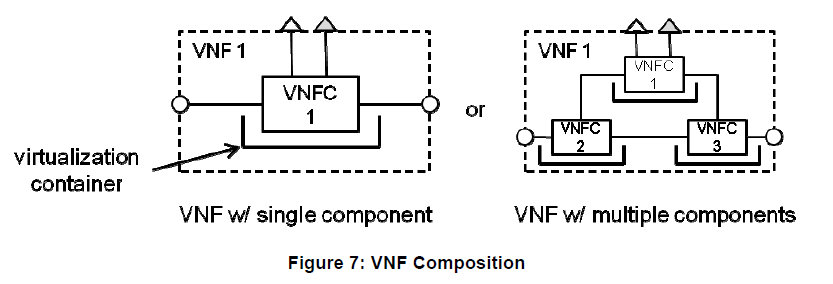
Then multiple combination exist:
- a) A given supplier may only deliver VNF hypervisor based
- b) a given supplier may deliver VNF Docker based
- b) A given supplier may deliver a mix of hypervisor based VNF and Docker based VNF
- c) A given supplier may deliver hybrid VNF: some VNFC are Docker based, some hypervisor based
- All suppliers may be of model a) or model b) , c) or d)
Similarly a service provider may decide to only deploy hypervisor based VNF, or only Docker based VNF, or support a mix of both. Whether direct or indirect mode is being used, the VNFM or the NFVO would then need to pass either an image with Guest OS for hypervisor based VM, or an image without Guest OS for containers like Docker.
A 4th case which is not described here is to support hybrid VNF with a mix of hypervisor based and Docker based VNFC.
The particular function embedded within a given NFV deployment can have many ways in which it could be eventually deployed. The choice of which deployment option is the most suited to a particular service provider’s environment will depend on not just the functional, but the non-functional aspects such as performance and security. Different virtualization options offer different levels of cost, performance along with different security integrity tradeoffs.
Although this short article has presented the process in a linear step-by-step deployment model, the potential choice of virtualization containers may lead to multiple iterations around the later steps as different virtualization choices are made in response to cost, performance and other operational concerns.
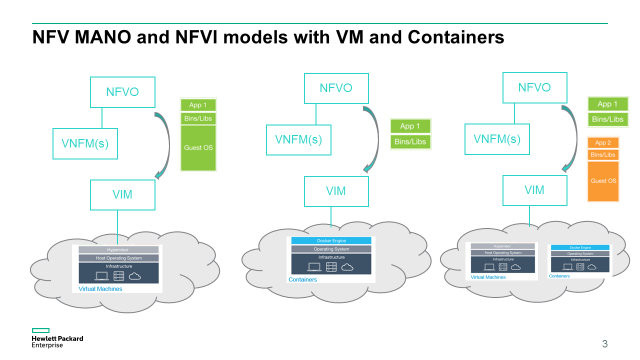
Consequently not only the supplier needs to deliver the proper VNF image to run either on the proper hypervisor versions supported, or container OS version supported, but it also needs to deliver the proper VNF Managers or VNF Manager scripts and artefacts to be compatible with the Service Provider MANO and NFVI environment. ETSI NFV supports these different models, then it is up to the implementation of the NFVO and the VIM to either adopt an implementation with a single VIM that supports both hypervisor and containers (ex OpenStack with Docker plug in), or have 2 separate VIMs (ex OpenStack for hypervisor and Kubernetes for Docker).
Based on these different combinations and what the service provider decides to support on his NFVI (NFV Infrastructure), the CI/CD will have to adapt and support more or less combinations and co-existence of different tools, packaging and interface implementations.
 Marie-Paule Odini holds a master's degree in electrical engineering from Utah State University. Her experience in telecom experience including voice and data. After managing the HP worldwide VoIP program, HP wireless LAN program and HP Service Delivery program, she is now HP CMS CTO for EMEA and also a Distinguished Technologist, NFV, SDN at Hewlett-Packard. Since joining HP in 1987, Odini has held positions in technical consulting, sales development and marketing within different HP organizations in France and the U.S. All of her roles have focused on networking or the service provider business, either in solutions for the network infrastructure or for the operation.
Marie-Paule Odini holds a master's degree in electrical engineering from Utah State University. Her experience in telecom experience including voice and data. After managing the HP worldwide VoIP program, HP wireless LAN program and HP Service Delivery program, she is now HP CMS CTO for EMEA and also a Distinguished Technologist, NFV, SDN at Hewlett-Packard. Since joining HP in 1987, Odini has held positions in technical consulting, sales development and marketing within different HP organizations in France and the U.S. All of her roles have focused on networking or the service provider business, either in solutions for the network infrastructure or for the operation.
Editor:
 Neil Davies is an expert in resolving the practical and theoretical challenges of large scale distributed and high-performance computing. He is a computer scientist, mathematician and hands-on software developer who builds both rigorously engineered working systems and scalable demonstrators of new computing and networking concepts. His interests center around scalability effects in large distributed systems, their operational quality, and how to manage their degradation gracefully under saturation and in adverse operational conditions. This has lead to recent work with Ofcom on scalability and traffic management in national infrastructures.
Neil Davies is an expert in resolving the practical and theoretical challenges of large scale distributed and high-performance computing. He is a computer scientist, mathematician and hands-on software developer who builds both rigorously engineered working systems and scalable demonstrators of new computing and networking concepts. His interests center around scalability effects in large distributed systems, their operational quality, and how to manage their degradation gracefully under saturation and in adverse operational conditions. This has lead to recent work with Ofcom on scalability and traffic management in national infrastructures.
Throughout his 20-year career at the University of Bristol he was involved with early developments in networking, its protocols and their implementations. During this time he collaborated with organizations such as NATS, Nuclear Electric, HSE, ST Microelectronics and CERN on issues relating to scalable performance and operational safety. He was also technical lead on several large EU Framework collaborations relating to high performance switching. Mentoring PhD candidates is a particular interest; Neil has worked with CERN students on the performance aspects of data acquisition for the ATLAS experiment, and has ongoing collaborative relationships with other institutions.
Fighting Your Way Through the Jungle of Intent
Fighting Your Way Through the Jungle of Intent
Pedro A. Aranda Gutiérrez and Diego R. López, Technology Exploration, Telefónica I+D
ABSTRACT: In this article we look at different SDN initiatives and how they are accommodating different projects exploring ways to express networking intents. We go through intent-related projects in the OpenDaylight eco-system and then look at the strategy of the ONF and OPNFV. To conclude, we provide a couple of thoughts of what intent should look like in the future.
1.1 Introduction
Intent Based Networking (IBN) is one of the current hot topics within the general trend on applying software-based techniques to networking. From its very inception, Intent has been described as “being descriptive, not prescriptive and, therefore, high-level enough to be independent of the underlying networking platform” (cf.[1] ). Other attractive properties attributed to intent include invariance and composability. But how much is hype and how much is really useful? Or, better said, is there something special to IBN? Something which can really make a difference in the way we interact with networks?
A plausible parallel to the development of IBN are programming languages. If in the beginnings, computers were programmed directly in machine code, most network appliances until recently have been programmed using a specific, low-level control channel like the current NETCONF[2] , OpenFlow [3] or vendor-specific interfaces like JunosScript [4] before. These interfaces sometimes use human-readable formats like YANG[5] . However, they are almost never easy to understand at a first glance, and by no means suitable for the laymen using networks, even when they are application programmers or system administrators.
In the early computing days, the first programming languages that appeared dubbed the structure and way of working of machine code and just provided a human-readable representation for it. It was later that programming languages that hid all the dirty details of implementing control structures, I/O and other elements of the interaction with computers to programmers started to appear. This evolution allowed programmers to write a program once and reuse it on different computers.
As with computers, a human-readable and more or less human-understandable way of representing the interaction with the network elements is desirable and we have seen a series of diverse initiatives claim the Intent flag for themselves.
1.2 A non-example
The ONF Atrium project is building an SDN-based router where users mix and match SDN controllers and Layer-2 switches to build a router with a Quagga daemon [6] implementing the required IP routing protocol suites. In order to provide a common abstraction to handle the different switches, some of which are OpenFlow-based, the project has defined an abstraction for the packet processing pipeline. This abstraction is called FlowObjectives. A question comes to mind -- whether this is Intent or not? In our opinion, this has little to do with Intent, since it just provides a common name to basic concepts of the pipeline like the next hop or a filter, and is therefore too low level. It continues to be prescriptive (e.g “do something specific for a packet in a switch”, as opposed to “do whatever is needed to provide a network service between two points”). As an analogy, it is difficult to imagine that someone would call object-oriented a macro package for an assembler.
1.3 Intent-based approaches
SDN controllers have reached the mainstream and now different Northbound Interface (NBI) developments claiming to be intent-based are popping up. ONOS has launched the ONOS Intents[7] , a framework that allows express “network control desires as policies instead of describing them through the mechanisms that implement them”. ONOS sees intent as a model that describes a request to alter network behaviour. This intent is then translated into FlowRules, which the ONOS framework again transforms into the commands for the different Southbound Interface (SBI) specific commands. ONOS Intents are purely programmatic and use the Java programming language. It’s arguable that this approach provides added value to the networking community at large, apart from providing yet another (low level) abstraction layer for SDN controller application programmers.
Another effort is the OpenSourceSDN Boulder project[8] . It defines an SDN controller independent NBIs that focuses on semantics and data models. Declarative and imperative approaches are supported.
Intent efforts in OpenStack are being pursued in different projects like Congress and Heat. OpenStack uses a so-called convergence engine as the central component that controls the infrastructure. In this effort, we also find the Group Based Policy effort. It defines collections of endpoints that underlie the same policies and provides reusable policy rule sets that can be layered based on user roles. From the point of view of readability, GBP is closer to a traditional command-line interface (CLI) than to a human language.
Last but not least, we have two projects in the Open Daylight (ODL) community that carry ‘intent’ in their names: Intent-based Network Modelling (IBNEMO)[9] and Network Intent Composition(NIC) [10] . NEMO has defined a structured, human understandable language to describe network scenarios. This language foresees a two-step process, firstly building node and link models which are then instantiated in a second step. Models are reusable, i.e. new models can be built starting from predefined models. NIC sees intent as the routing protocol for service. It defines subjects, actions, constraints and conditions, very much in the style of ONOS Intents. The NIC engine builds on a simple YANG model for Intent and receives intents as JSON files, which are human-readable but only conditionally human-understandable.
1.4 Brave new intent world?
Despite intent being in its beginnings, some interesting applications can be foreseen. One that is gaining interest is machine-learning applied to networking. A network using machine learning would extract information from the network to assess its state using systems previously trained by a human expert and autonomously take decisions to optimise itself. This approach implies the human expert would train the system by providing an initial set of human understandable statements, further refine the learning process by means of additional feedback, and possibly assess system behaviour by interpreting its autonomous decisions. In all these tasks, a declarative, high-level language to achieve human-machine communication would lower the entry barrier for this process.
As with any hype, intent can be a very empty buzzword to position a project in the SDN community and caution should be exercised when yet another project pops up and starts claiming ‘intent’. However, SDN is evolving very rapidly and, eventually, the most useful results from different initiatives will converge in well consolidated concepts and architectures. So, what could we expect from an all-embracing intent framework?
- The interface to operators should be human-understandable. With computing power increasing, parsing should not be a problem and facilitating a ‘human-in-the-loop’ approach will increase trust in the platform/solution/architecture.
- Intent should support composition. We have not gone all the way in introducing software development techniques in the network (e.g. agile programming techniques have translated in DevOps-style service development) to ignore the benefits of reusing of previously defined services to build new ones, in terms of reduced time-to-market, etc.
- Intent should not try to build the (networking) world from scratch. There are a lot of efforts to model network equipment and network services (e.g. using YANG). Any serious intent effort should build on what is available and not try to redefine everything from scratch.
References
[1] Intent: Don’t Tell Me What to Do! (Tell Me What You Want) https://www.sdxcentral.com/articles/contributed/network-intent-summit-perspective-david-lenrow/2015/02/
[2] http://www.rfc-editor.org/rfc/rfc4741.txt
[3] OpenFlow: Enabling Innovation in Campus Networks: http://doi.acm.org/10.1145/1355734.1355746
[5] YANG - A Data Modeling Language for the Network Configuration Protocol https://www.ietf.org/rfc/rfc6020.txt
[6] Quagga Routing Suite http://www.nongnu.org/quagga
[7] ONOS Intents https://wiki.onosproject.org/display/ONOS/Intent+Framework
[8] OpenSourceSDN: Project Boulder http://opensourcesdn.org/projects/project-boulder-intent-northbound-interface-nbi/
[9] Network Modeling Language: https://datatracker.ietf.org/doc/draft-xia-sdnrg-nemo-language/
[10] Network Intent Composition in ODL: http://es.slideshare.net/opendaylight/whats-the-intent
 Dr. Pedro A. Aranda Gutiérrez obtained his PhD at Universität Paderborn in 2013. He has been working in different positions in Telefónica I+D for the last 26 years, where he has participated in collaborative research projects both at national and European level. His past research topics include IP infrastructures and the BGP-4 protocol. Currently, he focuses on SDN and NFV research topics and is the Technical Coordinator of the FP7 NetIDE project, which is producing a multi-controller SDN development and runtime environment, which supports a controller-independent approach to SDN. His main interests currently include conflict resolution in SDN platforms and Intent-based Networking. In his free time, he likes to read, to enjoy music and to swim.
Dr. Pedro A. Aranda Gutiérrez obtained his PhD at Universität Paderborn in 2013. He has been working in different positions in Telefónica I+D for the last 26 years, where he has participated in collaborative research projects both at national and European level. His past research topics include IP infrastructures and the BGP-4 protocol. Currently, he focuses on SDN and NFV research topics and is the Technical Coordinator of the FP7 NetIDE project, which is producing a multi-controller SDN development and runtime environment, which supports a controller-independent approach to SDN. His main interests currently include conflict resolution in SDN platforms and Intent-based Networking. In his free time, he likes to read, to enjoy music and to swim.
 Dr. Diego R. López joined Telefonica I+D in 2011 as a Senior Technology Expert on network middleware and services. He is currently in charge of the Technology Exploration activities within the GCTO Unit of Telefónica I+D. Before joining Telefónica he spent some years in the academic sector, dedicated to research on network service abstractions and the development of APIs based on them. During this period, he was appointed as member of the High Level Expert Group on Scientific Data Infrastructures by the European Commission. His current interests are related to network virtualization, infrastructural services, network management, new network architectures, and network security. Diego is currently chairing the ETSI ISG on Network Function Virtualization, and acting as co-chair of the NFVRG within the IRTF. Apart from this, Diego is a more than acceptable Iberian ham carver, and extremely fond of seeking and enjoying comics, wines, and cheeses.
Dr. Diego R. López joined Telefonica I+D in 2011 as a Senior Technology Expert on network middleware and services. He is currently in charge of the Technology Exploration activities within the GCTO Unit of Telefónica I+D. Before joining Telefónica he spent some years in the academic sector, dedicated to research on network service abstractions and the development of APIs based on them. During this period, he was appointed as member of the High Level Expert Group on Scientific Data Infrastructures by the European Commission. His current interests are related to network virtualization, infrastructural services, network management, new network architectures, and network security. Diego is currently chairing the ETSI ISG on Network Function Virtualization, and acting as co-chair of the NFVRG within the IRTF. Apart from this, Diego is a more than acceptable Iberian ham carver, and extremely fond of seeking and enjoying comics, wines, and cheeses.
Editor:
Neil Davies is an expert in resolving the practical and theoretical challenges of large scale distributed and high-performance computing. He is a computer scientist, mathematician and hands-on software developer who builds both rigorously engineered working systems and scalable demonstrators of new computing and networking concepts. His interests center around scalability effects in large distributed systems, their operational quality, and how to manage their degradation gracefully under saturation and in adverse operational conditions. This has lead to recent work with Ofcom on scalability and traffic management in national infrastructures.
Throughout his 20-year career at the University of Bristol he was involved with early developments in networking, its protocols and their implementations. During this time he collaborated with organizations such as NATS, Nuclear Electric, HSE, ST Microelectronics and CERN on issues relating to scalable performance and operational safety. He was also technical lead on several large EU Framework collaborations relating to high performance switching. Mentoring PhD candidates is a particular interest; Neil has worked with CERN students on the performance aspects of data acquisition for the ATLAS experiment, and has ongoing collaborative relationships with other institutions.
IEEE Softwarization - September 2016
IEEE Softwarization - September 2016
A collection of short technical articles
Orchestration and Control Solutions in 5G: Challenges and Opportunities from a Transport Perspective
By Peter Öhlén, Ahmad Rostami, and Paola Iovanna, Ericsson Research
5G, the next generation mobile system, aims to provide unlimited access to information by people and a large variety of connected devices. We will see a massive growth in both traffic and the number of connected devices. Due to the multitude of services that will emerge, flexibility across all domains of networking and service functions will be much more important than before. New services will be developed and launched in shorter time cycles than current networks allow. This applies to end-user services which will continue to develop, but an increasing share will be for different internet of things applications, spanning from sensor networks to performance-critical industrial applications.
Fighting Your Way Through the Jungle of Intent
By Pedro A. Aranda Gutiérrez and Diego R. López, Technology Exploration, Telefónica I+D
In this article we look at different SDN initiatives and how they are accommodating different projects exploring ways to express networking intents. We go through intent-related projects in the OpenDaylight eco-system and then look at the strategy of the ONF and OPNFV. To conclude, we provide a couple of thoughts of what intent should look like in the future.
NFV: From CI/CD to Hypervisor or Container Based Deployments
By Marie-Paule Odini, HPE
With NFV, Network Function Virtualization, the whole process starts with the design of the Virtualized Network Function (VNF). This is generally done by a supplier of the VNF, typically a vendor. This VNF is then sold to a service provider who will integrate this VNF in his environment to enhance or deploy a new service.
NFV Service Chaining Challenges
By Djamal Zeghlache, UMR 5157 CNRS Samovar, Télécom SudParis, Université Paris Saclay, France
This letter presents a framework to automate the production of network services to address some of the challenges in the dynamic deployment of cloud and network services. A service management approach, using available open source components, a TOSCA extension for network services and a customized service function chaining module, is suggested for network service chaining.
NFV Service Chaining Challenges
NFV Service Chaining Challenges
Djamal Zeghlache, UMR 5157 CNRS Samovar, Télécom SudParis, Université Paris Saclay, France
Abstract- This letter presents a framework to automate the production of network services to address some of the challenges in the dynamic deployment of cloud and network services. A service management approach, using available open source components, a TOSCA extension for network services and a customized service function chaining module, is suggested for network service chaining.
Introduction
One of the challenges in software networks management is the design of an underlying framework to support and accelerate the production of applications and services by relying on Software Defined Networks (SDN), Network Function Virtualisation (NFV) and Cloud principles. Their success depends on the notion of abstraction and the availability of reliable service manager architectures fulfilling the agility, acceleration and automation requirements of next generation services.
The notion of abstraction is essential for agile services creation so that programmers consume an underlying service without knowing much about it other than its inputs, outputs and functionality. With abstraction, there are two types of creations. The first is the creation of the services themselves by assembling lower level services. The second is the generation of these lower level services, seen as abstractions (concepts or building blocks) by the higher level service. Agile services are created by first identifying and building the lower-level services upward from the resources. Once a catalog of these underlying services is defined and made available, high level service creation can use and assemble them into ‘‘services’’. A service is agile if the need to propagate changes in the low level services into the service definition is ideally eliminated or at least minimized. This means that requested service templates or workflows remain unaffected and unmodified by underlying changes. In the context of SDN, NFV and Cloud, this means that changes in real devices or virtual infrastructures (containers, networks and networking functions) have to be hidden from the service definition and workflows. Consequently, the provisioning of different abstractions and their deployment on different virtual platforms can vary (or can be altered) without changing the service and the way it is assembled or produced.
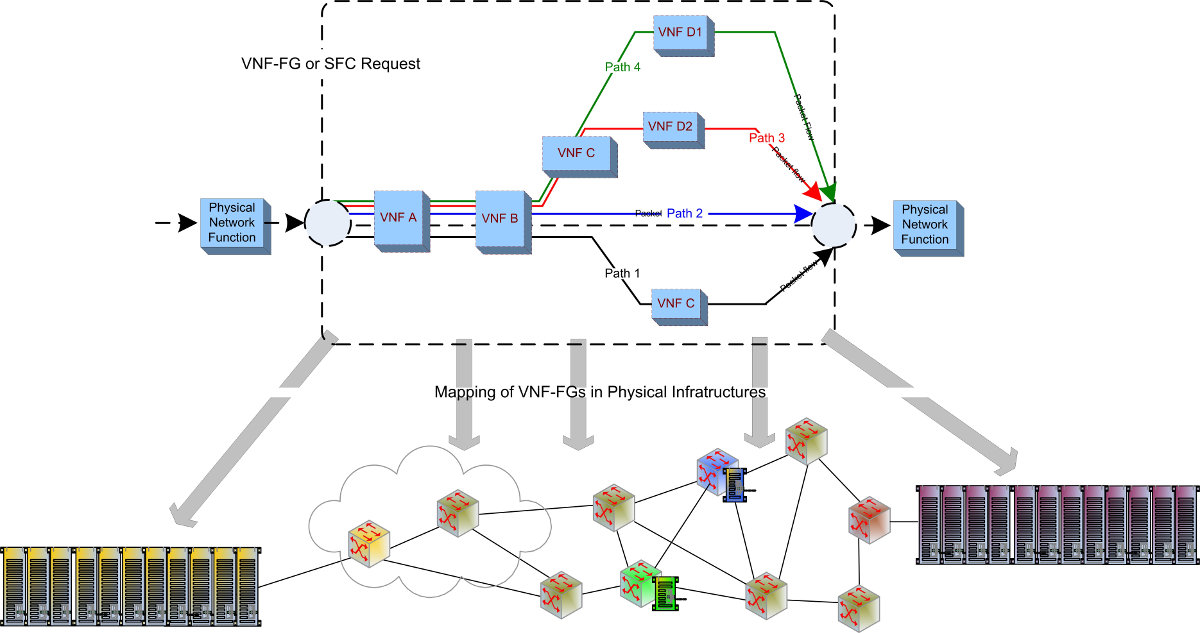
Figure 1. VNF-FG mapping on providers' infrastructures
A challenge, in NFV, that deserves special attention is the chaining of network services. Tenants can acquire, from providers, chained virtualized network functions and the means to steer and control their application and end users traffic flows. Figure 1 depicts a service function chain (SFC) or virtualized network function forwarding graph (VNF-FG) request with several VNFs and four application flows to steer into their respective forwarding paths 1 to 4. This is a good technical use case to derive appropriate agile services management architectures as it entails the description of network services (VNFs), their smart placement and the steering of their application flows through specified forwarding paths. VNF-FG establishment requires setting up of the containers or hosts of the VNFs themselves, their connectivity and the injection of rules to steer application flows into the desired forwarding paths. Designing a service management framework for VNF-FG can therefore fulfill most of the NFV needs and meet the requirements of network services chaining.
Service management in SDN and NFV
Service management in SDN and NFV is currently focused on the concept of orchestration to support service lifecycle management. The NFV Orchestrator in ETSI-NFV [1] is responsible for:
- Network Service (NS) lifecycle management (including instantiation, scale-out/in, performance measurements, event correlation, termination)
- Global resource management, validation and authorization of NFV Infrastructure (NFVI) resource requests
- Policy management for NS instances
NetCracker’s Service Orchestrator [2] enables end-to-end service provisioning for hybrid networks made of both virtualized SDN/NFV-based components and traditional network technologies. Other service life cycle management frameworks, such as ITILv3 [3] (Information Technology Infrastructure Library), that describe the life of an IT service (from planning and design to delivery and continuous improvement) are also used for IT lifecycle management. TOSCA (Topology and Orchestration Specification for Cloud Applications), from OASIS [4] [5] (Organization for the Advancement of Structured Information Standards), aims at enhancing the portability of cloud applications and services. TOSCA enables interoperable description of application and infrastructure cloud services independent of the suppliers creating the service, the cloud providers or the hosting technologies.
Despite these specifications, the merging of cloud, SDN and NFV in a cohesive system still requires further research and development. TOSCA addresses well cloud services and resources and their use to compose complex cloud services but network services are not part of its specification. There are no descriptors for networking services in TOSCA and no means to include virtualized network functions, their connectivity and chaining. There is a need to bridge and combine these domains by extending the service request descriptions to encompass cloud, network and control services.
Abstractions
One approach to provide abstractions for cloud and network services joint management is to extend the TOSCA data model with network services descriptors so it can also cover networking technologies. Current service descriptions and service templates that are likely to fulfill the agile service goal and can cover cloud, SDN and NFV are YAML [6], JSON and XML. YAML is the most expressive and more natural language for describing high level complex services when compared to XML and JSON.
In the current state of the art, the most appropriate and most expressive and extensible cloud service specification, to combine with YAML, seems to be TOSCA that uses a service specification framework (with service templates, languages and grammar) for cloud services. TOSCA defines key service templates and components for service description and service life cycle management:
- Topology Template: defines the structure of a service and consists of a set of Node templates that model the components of the workload and relationship templates that model the relations between the components
- Node Types and Relationship Types: describe the possible kinds of components and their relationships. These types allow defining lifecycle operations to implement the behavior “an orchestration engine” can invoke when instantiating a service template (e.g. a node type can provide lifecycle operations: ‘create instance’, ‘start’, ‘stop’...)
- Plans: defined in a Service Template, describe the management aspects of service instances, especially their creation and termination. Plans in TOSCA use existing workflow languages such as BPMN 2.0 or the BPEL 2.0. TOSCA recommends BPMN 2.0 to model management plans as it offers a standardized graphical rendering and does not force the workflow graph to be acyclic [7]. Plans are modeled by application developers or experienced operators [8]. TOSCA defines three types of management plans: build, modification, and termination plans
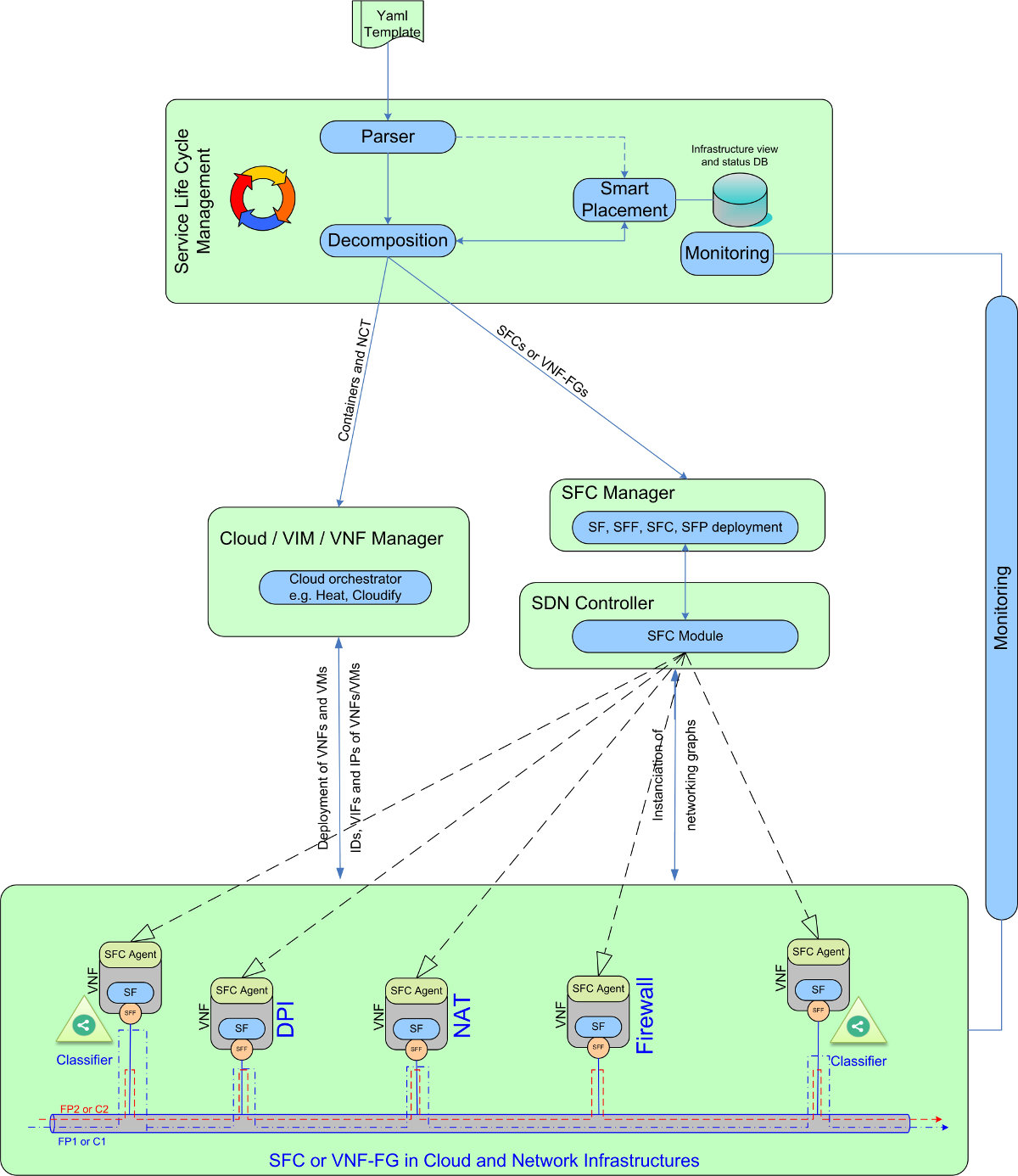
Figure 2: Service Life Cycle Management for SFC or VNF-FG services
TOSCA template extension
Figure 3 “block A” represents the original TOSCA grammar used for abstract representation of cloud applications. The topology template can be seen as a directed graph with Node Templates as vertices and Relationship Templates as edges connecting them. The Group Templates form sub-graphs of the Topology Template graph. The node template is an abstraction of the application or the user requested resource. The TOSCA data model, limited to cloud applications, has to be extended to support the representation of VNFs and their stitching to form a VNF service chain. A proposed extension of the TOSCA grammar and data model is depicted in blocks B and C of Figure 3.
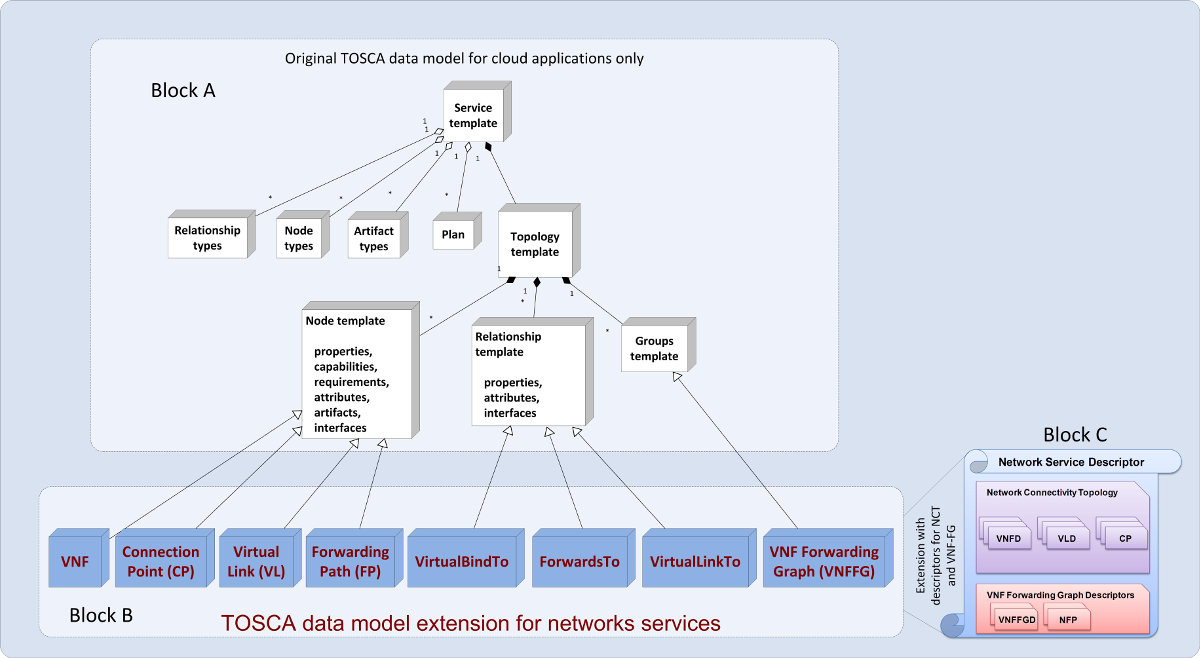
Figure 3: Extended Tosca data model for NFV paradigm
In the ETSI-NFV standard and terminology, there are two types of graphs composing the network service descriptor [1] and these must be included in the TOSCA model (blocks B and C of Figure 3):
- The first one is the network connectivity topology (NCT) that specifies the VNF nodes that compose the global service and the connection between them using the virtual link (VL) concept. Each VL is connected to a VNF through the connection point (CP) which represents the VNF interface.
- The second type is the VNF Forwarding Graph (VNF-FG) established on top of the Network Connectivity Topology. The VNF-FG is composed of network forwarding paths (NFP) that are ordered lists of Connection Points forming a VNF chain.
The proposed TOSCA extension (block B of Figure 3) and the associated parser (see Figure 2) use the notion of node template by inheriting new nodes to represent the VNF, CP, VL and NFP components. The VNF node is characterized by the associated VM and the network function appliance that will be hosted on the VM. The network function appliance is represented as an artifact element in the TOSCA grammar. The VL represents the virtual link that interconnects the VNFs. To establish this connection, we use the new inherited relationship nodes to bind the CP to the VNF (the “virtualBindTo” relationship) and to link the CP to the VL (using the “VirtualLinkTo” relationship). The forwarding path (FP), inherited from the node template, is modeled as an ordered list of CPs forming a sequence of VNFs that will be traversed by packets or traffic flows. The FP is connected to CPs by the “ForwardsTo” relationship. Each VNF forwarding graph includes a list of FPs that are interdependent and have common characteristics (e.g. several FPs have the same source and destination IP addresses). For this reason, the VNF-FG is modeled as a Group and thus inherits from the Groups Template of the original TOSCA model. The proposed extension is used by the service life cycle management depicted in Figure 2 to ensure orchestration of both cloud and network services and the provisioning, instantiation and management of SFCs or VNF-FGs.
A SLC manager
Existing cloud resource orchestration frameworks like Cloudify and OpenStack Heat are mature enough for traditional cloud services (compute, memory, storage) but are unable to provide service function chaining [9][10] (SFC) across networked cloud infrastructures to multiple tenants in a B2B2C context. The architecture in Figure 2 takes advantage of existing Cloud orchestration and SDN management tools and introduces the 'missing pieces' and a service lifecycle (SLC) manager to support complex applications and enable service function chaining over cloud, SDN and NFV environments. The SLC manager invokes the cloud orchestrator to set up virtual resources acting as containers for user applications and virtualized network functions.
The SLC manager interacts also with the SDN controller to set up the required virtual network functions and the forwarding graphs. The key modules of the SLC manager are the:
- Tosca Parser: is an extended version of the basic Tosca parser so it can deal with both cloud and network resources.
- Decomposition Module: divides the resources into resources/services to be deployed by the Cloud Orchestrator and networking resources/chaining paths to be deployed by the SDN manager.
- Cloud Orchestration Translator: transforms requested Cloud resources to the template language of the Cloud Orchestrator (Cloudify or Heat).
- Cloud Resources Instantiation: communicates with the Cloud Orchestrator to instantiate the resources.
- SFC Manager: deals with networking and chaining demands by invoking the SDN controller to instantiate the resources.
The SLC Manager translates the NCT graph to the language used by the Cloud orchestrator (Cloudify blueprint, Heat Orchestration Template…). The SLC manager sends the created template to the cloud orchestrator to instantiate cloud resources. The VNF-FG, that defines the requested chains and their forwarding paths, is only deployed once the VMs are successfully instantiated by the cloud orchestrator and provided with addresses. The SFC manager deploys the VNF-FG by invoking the SDN controller that achieves the stitching of the VNFs (connecting the SFs more precisely). The proposed SFC manager depicted in Figure 2 interacts with the SFC module (an extension of ODL SFC module) to deploy the SFCs. The SFC manager deploys the SFs (VNFs); the SFFs (CPs); the SFCs (VNF-FGs) and the SFPs (FPs). These configurations are then sent by ODL to the VMs through the SFC agent.
Conclusions
This letter presents a possible agile service management approach for cloud and networks services production using readily available open source platforms and software, a TOSCA extension for network services and a customized ODL SFC Manager module. The presented orchestration principles and framework are sufficiently generic to build future agile SFC life cycle management architectures.
Acknowledgment
The approach and architecture presented in this letter is the result of joint work with Imen Grida Ben Yahia from Orange Labs and Marouen Mechtri who master minded the concepts and implemented the framework. The original study received partial funding from Orange labs and the French FUI.
References
[1] ETSI GS NFV-MAN 001 http://www.etsi.org/deliver/etsi_gs/NFV-MAN/001_099/001/01.01.01_60/gs_nfv-man001v010101p.pdf
[2] NetCracker Service Orchestrator, http://www.netcracker.com/
[3] OGC-V3-Intro: “The Official Introduction to ITIL Service Lifecycle” (TSO, 2007, Fifth edn. 2007)
[5] http://docs.oasis-open.org/tosca/TOSCA/v1.0/TOSCA-v1.0.pdf
[6] http://yaml.org/spec/current
[7] Kopp, O., Martin, D., Wutke, D., Leymann, F.: The Difference Between Graph-Based and Block-Structured Business Process Modelling Languages. Enterprise Modelling and Information Systems 4 (1) (2009) 3–13
[8] Kopp, O., Binz, T., Breitenbücher, U., & Leymann, F. (2012). BPMN4TOSCA: A domain-specific language to model management plans for composite applications. In J. Mendling, & M. Weidlich (Eds.), Business process model and notation (Vol. 125 of Lecture Notes in Business Information Processing, pp. 38—52).
[9] Heat ‘OpenStack Orchestration service’, https://wiki.openstack.org/wiki/Heat
[10] Cloudify project. http://getcloudify.org/
 Professor Djamal Zeghlache graduated from SMU in Dallas, Texas in 1987 with a Ph.D. in Electrical Engineering and joined the same year Cleveland State University as an Assistant Professor. In 1992 he joined the Networks and Services Department at Telecom SudParis of Institut Telecom where he currently acts as Professor and Head of the Wireless Networks and Multimedia Services Department. His current interests and research activities concern network architectures, protocols and interfaces to ensure smooth evolution towards loosely coupled future networks and cloud architectures. He is currently addressing optimization, deployment, control and configuration challenges in cloud, SDN and NFV environments and systems.
Professor Djamal Zeghlache graduated from SMU in Dallas, Texas in 1987 with a Ph.D. in Electrical Engineering and joined the same year Cleveland State University as an Assistant Professor. In 1992 he joined the Networks and Services Department at Telecom SudParis of Institut Telecom where he currently acts as Professor and Head of the Wireless Networks and Multimedia Services Department. His current interests and research activities concern network architectures, protocols and interfaces to ensure smooth evolution towards loosely coupled future networks and cloud architectures. He is currently addressing optimization, deployment, control and configuration challenges in cloud, SDN and NFV environments and systems.
Editor:
 Professor Shashikant Patil is a prominent educationist and Teacher. He is a renowned Engineer, researcher and scientist. He has received numerous accolades for his valuable contributions and achievements in education and research. Prof. Patil graduated Electronics Engineering from North Maharashtra University in 1997 and joined as a Lecturer in Government Polytechnic Mumbai in 1999. After completing his Masters in from Dr Babasaheb Ambedkar Technological University Lonere, he joined NMIMS and later on appointed as an Associate Professor and Head of the Department. He is currently serving as an Associate Editor, Editorial Board Member, Technical Advisory Board Member, Potential Peer Reviewer and Journal Referee on at least 50 Journals. He is also having an association with Elsevier Editorial Series, Taylor and Francis, SpringerLink Journals as a potential Peer Reviewer and Journal Referee. He is also associated with IEEE, ACM, CSI, ISTE, NHRDN, E4C and IETE as Professional member and nominated as an affiliate member on various committees of IEEE SPS and ComSoc. He has participated in 36 Teacher Training Programs/ Refresher courses like STTPs/ CEPs/QIPs/Conferences / Workshops in IITs and reputed institutes. A stickler for quality, team builder to the core and a natural motivator with perseverance and integrity. Commands excellent communication skills that have been honed through interacting with people at various levels. He is recipient of Best Researcher Award 2014 of SVKMs NMIMS Shirpur. In addition to this he had been nominated as IEEE Day 2015 Section Ambassador for region 10. Recently has been selected as a Member Executive Committee on IEEE CSI India Council as well as Core Team Member of Social Media and Online Content Management Team, Visibility Committee of IEEE SPS Society at International Level. He has published around 31 articles in various conferences and journals at National and International level. This year he has been selected as Regional Lead Ambassador for region 10 for IEEE Day 2015 event. He is also heading SVKMs NMIMS Bosch Centre of Excellence in Automation Technologies Shirpur Campus. He is member IEEE RFID Technical Council and SIG Member of IOT. His research interests are Signal Processing and Imaging. He is also heading SVKMs NMIMS Bosch Centre of Excellence in Automation Technologies Shirpur Campus. He is member IEEE RFID Technical Council and SIG Member of IOT. His research interests are Signal Processing and Imaging. He is also serving as an Associate Editor on IEEE RFID Journal; IEEE SDN Journal; IEEE RFID Steering Committee.
Professor Shashikant Patil is a prominent educationist and Teacher. He is a renowned Engineer, researcher and scientist. He has received numerous accolades for his valuable contributions and achievements in education and research. Prof. Patil graduated Electronics Engineering from North Maharashtra University in 1997 and joined as a Lecturer in Government Polytechnic Mumbai in 1999. After completing his Masters in from Dr Babasaheb Ambedkar Technological University Lonere, he joined NMIMS and later on appointed as an Associate Professor and Head of the Department. He is currently serving as an Associate Editor, Editorial Board Member, Technical Advisory Board Member, Potential Peer Reviewer and Journal Referee on at least 50 Journals. He is also having an association with Elsevier Editorial Series, Taylor and Francis, SpringerLink Journals as a potential Peer Reviewer and Journal Referee. He is also associated with IEEE, ACM, CSI, ISTE, NHRDN, E4C and IETE as Professional member and nominated as an affiliate member on various committees of IEEE SPS and ComSoc. He has participated in 36 Teacher Training Programs/ Refresher courses like STTPs/ CEPs/QIPs/Conferences / Workshops in IITs and reputed institutes. A stickler for quality, team builder to the core and a natural motivator with perseverance and integrity. Commands excellent communication skills that have been honed through interacting with people at various levels. He is recipient of Best Researcher Award 2014 of SVKMs NMIMS Shirpur. In addition to this he had been nominated as IEEE Day 2015 Section Ambassador for region 10. Recently has been selected as a Member Executive Committee on IEEE CSI India Council as well as Core Team Member of Social Media and Online Content Management Team, Visibility Committee of IEEE SPS Society at International Level. He has published around 31 articles in various conferences and journals at National and International level. This year he has been selected as Regional Lead Ambassador for region 10 for IEEE Day 2015 event. He is also heading SVKMs NMIMS Bosch Centre of Excellence in Automation Technologies Shirpur Campus. He is member IEEE RFID Technical Council and SIG Member of IOT. His research interests are Signal Processing and Imaging. He is also heading SVKMs NMIMS Bosch Centre of Excellence in Automation Technologies Shirpur Campus. He is member IEEE RFID Technical Council and SIG Member of IOT. His research interests are Signal Processing and Imaging. He is also serving as an Associate Editor on IEEE RFID Journal; IEEE SDN Journal; IEEE RFID Steering Committee.
Orchestration and Control Solutions in 5G: Challenges and Opportunities from a Transport Perspective
Orchestration and Control Solutions in 5G: Challenges and Opportunities from a Transport Perspective
Peter Öhlén, Ahmad Rostami, and Paola Iovanna, Ericsson Research
5G, the next generation mobile system, aims to provide unlimited access to information by people and a large variety of connected devices. We will see a massive growth in both traffic and the number of connected devices. Due to the multitude of services that will emerge, flexibility across all domains of networking and service functions will be much more important than before [JLT-2016]. New services will be developed and launched in shorter time cycles than current networks allow. This applies to end-user services which will continue to develop, but an increasing share will be for different internet of things applications, spanning from sensor networks to performance-critical industrial applications.
Next Generation Mobile Networks Alliance [NGMN-WP], ITU-R, and 5G Infrastructure Public Private Partnership [5G-PPP] have concluded that bit rates up to 10 Gbps and a significant reduction in latency will be needed for the most demanding services in 5G. At the same time, networks need to be flexible enough to accommodate different services in a cost-effective manner.
In this context, software-defined networking (SDN) is a promising approach to provide the needed flexibility to serve the diverse requirements of future services.
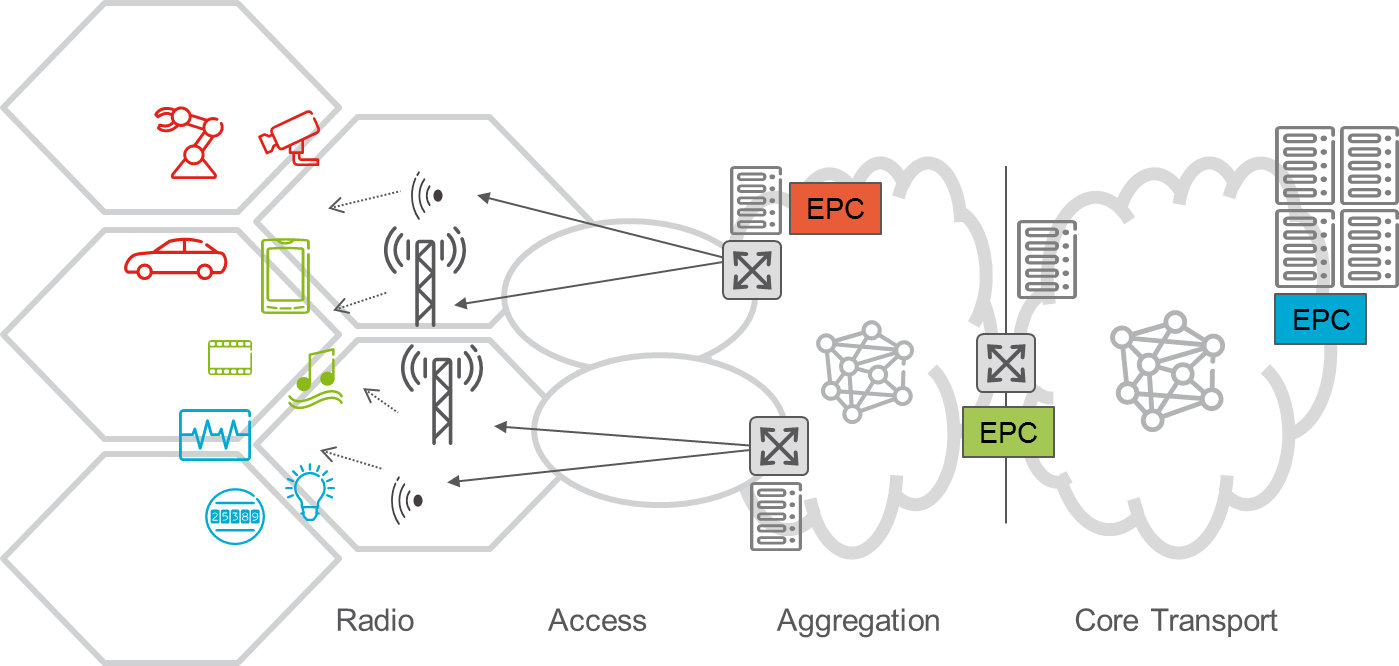
Figure 1. Network scenario indicating location of different nodes, and slices for different applications like critical machine-type communication (MTC) (red), enhanced broadband (green) and sensor networks (blue)
End-to-end slicing
One important concept within 5G is network slicing, where a specific service is hosted within a dedicated slice containing all the physical and virtual resources needed [NGMN-slicing]. If the service requires high availability and performance characteristics like high bandwidth and low latency, the slice will be setup to fulfil these requirements, as illustrated in Figure 1. This applies both to network performance across radio and transport networks, but also characteristics and placement of network functions at the right location in a distributed datacenter infrastructure. Such a setup with more demanding requirements obviously comes at a resource cost which needs to be motivated by a business need and a corresponding value for the services provided to the end-user, e.g. a high-touch Internet of things (IoT) application. Examples of such services include control of industrial machinery, and some transportation applications where real-time control loops are operated from a remote location and a high-definition video stream is sent to an operations center.
Other IoT applications have different requirements – for example metering and sensor applications – where cost is a more challenging point. The transport network and the service functions for such applications would be setup in a different way. It leads still to the need to share the infrastructure across applications that span the entire range of requirements, giving more ways to create value and revenue from infrastructure investments. Coordinated resource allocation can also optimize the utilization and thus, the cost. So, effective methods and features for network sharing is a key enabler, and it is important that different control and management system across different infrastructure domains can work together to create end-to-end (E2E) services without manual setup and configuration. The need for network sharing leads also to the requirement of isolation between different services, to ensure that services continue to function as expected even in situation where there is overload in other services.
Orchestration and control architecture
Dynamic, automated and resource-efficient setup of E2E connectivity, as required by many use cases of 5G, is hard to realize with the rigid architecture of current networks. Software defined networking (SDN) is a promising technology to support the required programmability. While SDN principles like abstraction and programmability have been successfully adopted in individual technology domains, little has been achieved for adopting SDN for orchestration across multiple domains to create the E2E programmability.
Depending on the required level of flexibility and the acceptable level of complexity there are several possibilities for creating E2E orchestration based on SDN. Figure 2 presents an SDN-based, hierarchical, multi-domain orchestration architecture, which is designed to fulfill the requirements of 5G on programmability and operational scalability [ComMag-2016]. At the bottom layer of the orchestration architecture in Figure 2 there are resources, i.e. radio, transport and compute/storage, distributed across different domains. A domain-specific controller controls resources within an individual domain in a programmable way. The controllers expose abstract presentations of the resources in corresponding domains towards the orchestrator. The orchestrator aggregates these into an E2E presentation of abstract resources and exposes it towards various networking applications over a single, programmatic application-programming interface (API). Networking applications can utilize this API for requesting E2E services, which may span across various domains. The orchestrator is responsible for decomposing such service requests into required resources within individual domains and then asks the corresponding controllers for the required configurations. Additionally, the orchestrator will take care of mapping the E2E service level agreements (SLAs) to resource and quality-of-service (QoS) requirements within the different domains as well as the life-cycle management of different parts of services.
Virtualization layers on top of the controllers and orchestrator in Figure 2 present an important feature of the architecture. In particular, these layers allow virtualizing radio, transport and cloud resources for creating E2E slices. In this approach, different slices can be created to support networking applications with different requirements on resources. This enables sharing of the same infrastructure among multiple services in an efficient and flexible manner.
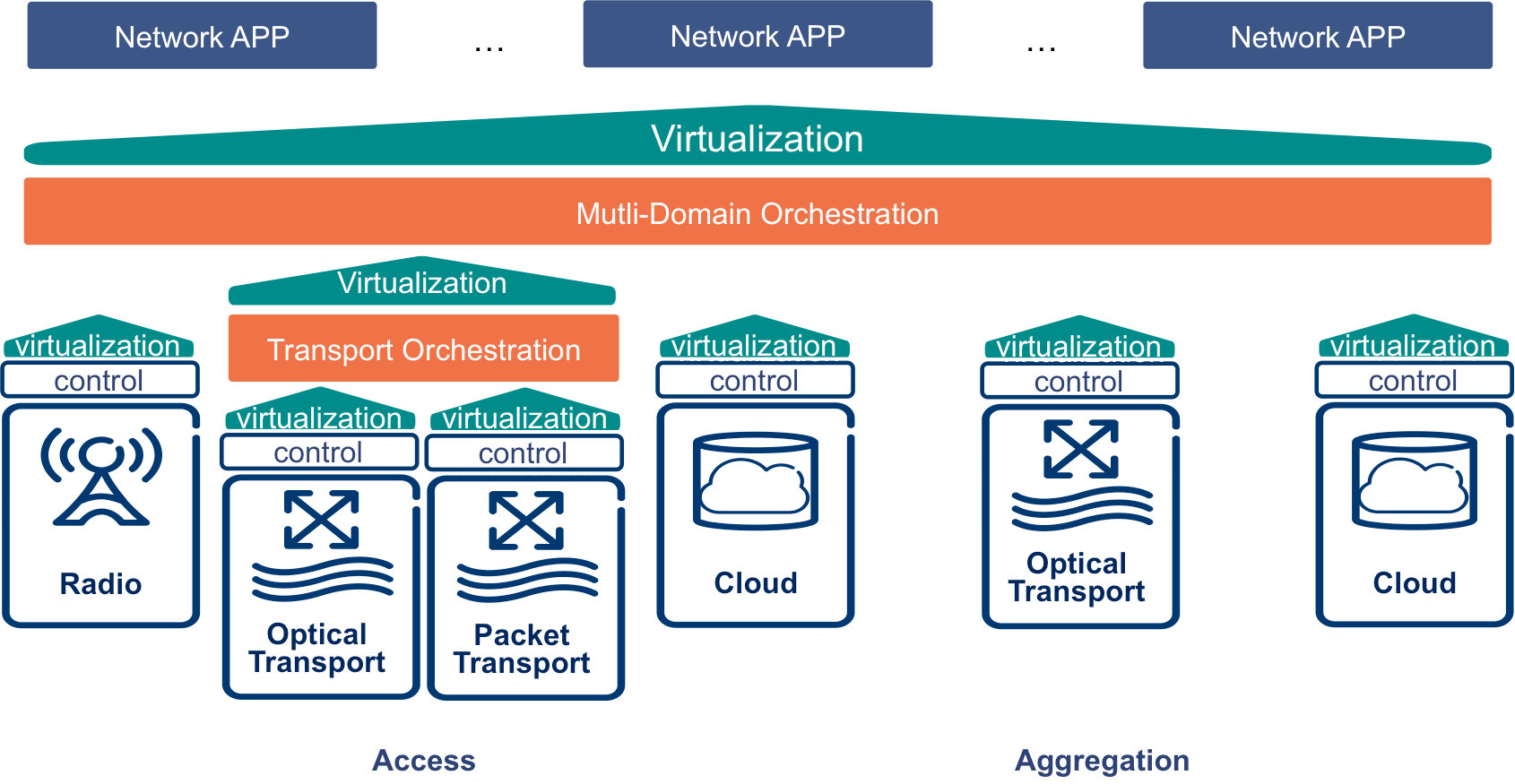
Figure 2. Hierarchical end-to-end orchestration across radio-access network (RAN), transport and cloud.
Inter-operator orchestration
In a scenario with multiple operators, there are additional issues compared to what is described above. Nevertheless, it will be quite relevant to enable cooperation between operators to provide E2E services towards the end customers. This means that agreements have to be established between operators for a full E2E service deployment, accompanied by suitable business models. For full automation, there is a need to setup such relations using new interfaces between different operators, which include clearly defined SLAs with the required QoS parameters across multiple managed networks. However, cooperation between operators is subject to both technical (e.g., heterogeneity of network infrastructure) and commercial constraints (e.g. confidentiality on resources, pricing, risk avoidance). For this reason, the multi-operator interaction cannot be seen as a straightforward extension of the multi-domain solution previously described. To provide E2E services spanning multiple operators could be difficult since a single operator does not have complete view of the network. Moreover, different operator’s strategies and conflicting interests could complicate the cooperation among operators, which is a fundamental prerequisite to jointly compose the end-to-end service. The existing solutions are based on an a priori E2E vision of all operator domains to be crossed to reach final destinations. Currently, mainly best-effort network service is supported, through the Border Gateway Protocol (BGP). The wide use of BGP would make it attractive to extend this best-effort protocol to include more granular SLA parameters for inter-domain routing. This would also simplify integration with legacy domains setting the stage for incremental upgrade of the inter-operator capabilities. However, there are important constraints in BGP, which limit inter-carrier QoS connectivity provisioning: The lack of flexibility (it is not possible to choose multiple paths between two remote autonomous systems), the scalability (enormous growth of globally advertised address prefixes) and confidentiality issues (e.g., resource state).
A possible option for multi-operator interworking could be based on a flat architecture where each operator can interface to other operator to establish their relations. Once the service relation has been setup, the runtime control can follow the hierarchical approach above, or a peer model. In Figure 3 a mix of possible scenarios for multi-operator interworking are shown providing a high level architecture, where each operator can ask for a service with clearly defined SLA. In case the operator A requests a radio service from operator B, the interface (IF1) is based on radio requirements. In case the operator B which owns no transport, requests a service from transport operator C, the interface (IF2) would specify transport parameters. In principle IF1 and IF2 could be a suitable extension of BGP to be adopted for radio and transport service request respectively, but novel interfaces and approaches could be a valid alternative.
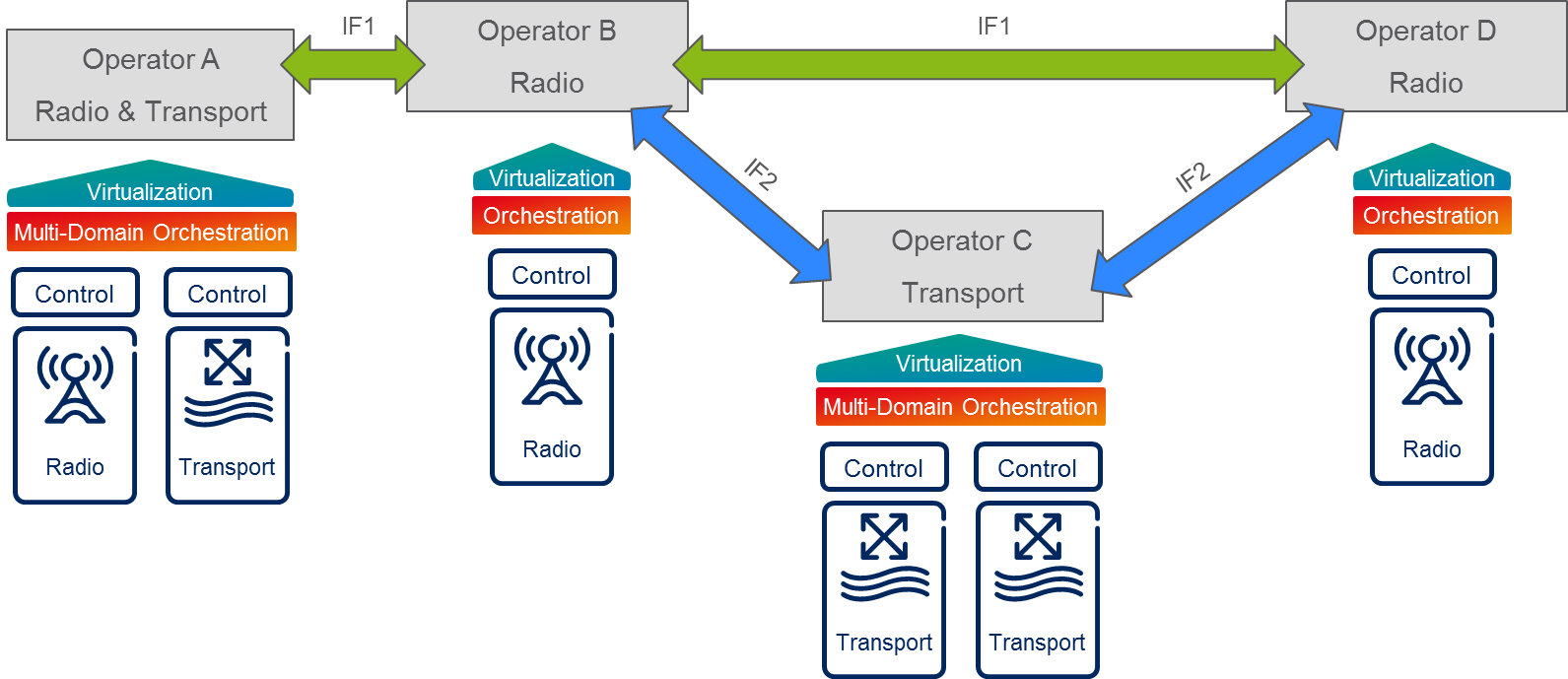
Figure 3. Examples of possible scenarios for multi-operator interworking
Conclusions and open issues
In future networks, and in 5G in particular, the interworking and dynamic coordinated control across different technology domains, and different operators will become more important to fulfill service requirements. A key area to address is how to manage the complexity and enable programmable control and automation. Among the issues that need consideration and efficient solutions are
- Abstraction of infrastructure resources and capabilities
- Information sharing between different domains and related protocols
- End-to-end resource and service orchestration enabled by programmatic APIs
- Consideration of business models between operators to enable the required automation.
In the end, different technologies like the ones described in this letter will be needed to enable this, taking both new technologies and legacy networks into account. This will make possible a step-by-step enhancement of the joint infrastructure to fulfill the needs of future services connected over 5G.
References
[JLT-2016] P. Öhlén et al., "Data Plane and Control Architectures for 5G Transport Networks," Journal of Lightwave Technology, vol. 34, no. 6, pp. 1501-1508, March 2016.
http://dx.doi.org/10.1109/JLT.2016.2524209
[NGMN-WP] NGMN Alliance. (Feb 2015), NGNM 5G White Paper [Online]
https://www.ngmn.org/uploads/media/ NGMN_5G_White_Paper_V1_0.pdf
[5G-PPP] 5G PPP. (Mar. 2015), 5G vision: The next generation of communication networks and services [Online].
http://5g-ppp.eu/wp-content/uploads/2015/02/5G-Vision-Brochure-v1.pdf
[NGMN-slicing] “Description of Network Slicing Concept”, NGMN Alliance, version 1.0.
https://www.ngmn.org/uploads/media/160113_Network_Slicing_v1_0.pdf
[ComMag-2016] A. Rostami et al., “Orchestration of RAN and Transport Networks for 5G: An SDN Approach,” IEEE Communications Magazine, vol. 54, no. 10, Oct. 2016 (to appear).
 Peter Öhlén is a principal researcher at Ericsson Research. He received a M.Sc. degree in engineering physics from the Royal Institute of Technology in 1995. In 2000 he received a Ph.D. in Photonics, also from the Royal Institute of Technology. He has been with Ericsson since 2005.
Peter Öhlén is a principal researcher at Ericsson Research. He received a M.Sc. degree in engineering physics from the Royal Institute of Technology in 1995. In 2000 he received a Ph.D. in Photonics, also from the Royal Institute of Technology. He has been with Ericsson since 2005.
With more than 15 years of experience in telecommunications, he has worked with research and development in transport networks, network control, SDN, fiber access technologies, fiber-optic transmission, radio networks, optical and electronic subsystem design, simulation methods, project and program management. He was heavily involved in the standardization of 10Gb Ethernet and in the FSAN group for standardization of XG-PON systems. His current research focuses on network control, cross-domain orchestration and 5G transport networks.
 Ahmad Rostami is a senior researcher in networking technologies at Ericsson Research, where he leads activities in the area of programmable networks as well as control and orchestration architectures and protocols for 5G networks. Before joining Ericsson, he worked at the Technical University of Berlin (TUB) as a senior researcher and lecturer. At the university his areas of research covered network control and software defined networking (SDN) technologies. He holds a Ph.D. (summa cum laude) in Communication Networks from TUB, and a M.Sc. in Electrical Engineering (Communication Networks) from Tehran Polytechnic.
Ahmad Rostami is a senior researcher in networking technologies at Ericsson Research, where he leads activities in the area of programmable networks as well as control and orchestration architectures and protocols for 5G networks. Before joining Ericsson, he worked at the Technical University of Berlin (TUB) as a senior researcher and lecturer. At the university his areas of research covered network control and software defined networking (SDN) technologies. He holds a Ph.D. (summa cum laude) in Communication Networks from TUB, and a M.Sc. in Electrical Engineering (Communication Networks) from Tehran Polytechnic.
 Paola Iovanna received the degree in electronics engineering from the University of Roma “Tor Vergata” in 1996. From 1995 to 1997 she collaborated with the research center FUB of Rome, working on fiber-optic communications and optical networking. From 1997 to 2000 she worked in “Telecom Italia” where she was involved in experimentation of new services based on different access technologies (as XDSL, Frame Relay, optical). Since 2000 she joined Ericsson in the Research department where she dealt with networking and design solutions for packet and optical technology ( GMPLS, MPLS, Ethernet ). From 2009 to 2012 she was responsible to carry out research projects on packet and optical routing, control-plane and path computation solution. From 2012 she is responsible to define and prototype SDN solutions for multi-domain transport in collaboration with customers. In the framework of such activities she realized demonstrators and prototypes as well. From 2014 she leads research team to define transport networking and control solutions for 5G. She is actively involved in European project and is Technical Program Committee of international conferences like ECOC. She holds more than 50 patents on routing, traffic engineering systems, and PCE solutions for packet-opto networks based on GMPLS, and multi-domain SDN transport, fronthaul and backhaul solutions for 5G, and she is author of several tens of publications on either international scientific journals or conferences.
Paola Iovanna received the degree in electronics engineering from the University of Roma “Tor Vergata” in 1996. From 1995 to 1997 she collaborated with the research center FUB of Rome, working on fiber-optic communications and optical networking. From 1997 to 2000 she worked in “Telecom Italia” where she was involved in experimentation of new services based on different access technologies (as XDSL, Frame Relay, optical). Since 2000 she joined Ericsson in the Research department where she dealt with networking and design solutions for packet and optical technology ( GMPLS, MPLS, Ethernet ). From 2009 to 2012 she was responsible to carry out research projects on packet and optical routing, control-plane and path computation solution. From 2012 she is responsible to define and prototype SDN solutions for multi-domain transport in collaboration with customers. In the framework of such activities she realized demonstrators and prototypes as well. From 2014 she leads research team to define transport networking and control solutions for 5G. She is actively involved in European project and is Technical Program Committee of international conferences like ECOC. She holds more than 50 patents on routing, traffic engineering systems, and PCE solutions for packet-opto networks based on GMPLS, and multi-domain SDN transport, fronthaul and backhaul solutions for 5G, and she is author of several tens of publications on either international scientific journals or conferences.
Editor:
 Chris Hrivnak is a senior member of the Institute of Electrical and Electronic Engineers (IEEE) and IEEE Photonics Society. He is also a member of the IEEE Cloud Computing Community, IEEE Life Sciences Community, IEEE Smart Grid Community, the IEEE Software Defined Networks (SDN) Community, IEEE Internet of Things (IoT) Technical Community and the IEEE Internet Technology Policy Community.
Chris Hrivnak is a senior member of the Institute of Electrical and Electronic Engineers (IEEE) and IEEE Photonics Society. He is also a member of the IEEE Cloud Computing Community, IEEE Life Sciences Community, IEEE Smart Grid Community, the IEEE Software Defined Networks (SDN) Community, IEEE Internet of Things (IoT) Technical Community and the IEEE Internet Technology Policy Community.